We're thrilled to announce Mayson's Pre-Seed funding round!
We're thrilled to announce Mayson's Pre-Seed funding round!
What breaks when your app suddenly gets a lot of users?
What breaks when your app suddenly gets a lot of users?

When an app suddenly gets a lot of users, the parts that break first are almost always the database, the authentication system, and the server capacity, not because the code is wrong, but because these components were never stress-tested beyond the traffic levels the builder had in mind when they set the app up. The code that worked fine for 50 users starts behaving differently at 5,000, and the differences follow a predictable sequence. Engineers who've watched it happen can describe it in advance. This article does that.
Why sudden traffic is a different problem from steady growth
Steady growth gives infrastructure time to gradually reveal its limits. You notice that database queries are getting slower. You add an index. Response times improve. You notice the server is running hot. You upgrade the instance. You stay ahead of the problem because the problem arrives incrementally.
Sudden traffic doesn't give you that time. A product gets featured in a newsletter with a large readership. A tweet goes viral. A journalist covers the launch. Ten thousand people try to use an app that was built for a hundred, and they all try at the same moment. The infrastructure doesn't degrade; it collapses, because every weakness that would have revealed itself gradually over weeks arrives simultaneously in the first twenty minutes.
The failure sequence is also different. With gradual growth, you fix one thing at a time. With a traffic spike, you often can't fix anything in real time because the cascade has already started, and one failure is causing the next before you've diagnosed the first.
I've watched this happen from the inside once, during a payment infrastructure launch that got picked up by a financial news outlet the morning it went live. We had load-tested to three times the expected traffic. The actual spike was eleven times the expected traffic. The sequence of what broke, in what order, and why is something I can still describe in detail, and the sequence is almost always the same regardless of the app.
The database under pressure: what happens and why it's usually the first thing to go
The database fails first in almost every traffic spike. Understanding why requires knowing what a database connection pool is.
A connection pool is a set of pre-established connections between your application server and your database. Think of it as a limited number of phone lines between two offices. When your app needs to talk to the database, it borrows one of those lines, uses it, and returns it. If all the lines are in use when a new request arrives, that request waits. If it waits too long, it times out, and the user sees an error.
Under normal traffic, connection pools are sized generously relative to demand. Under a spike, every concurrent user is making requests that need database access, loading their profile, checking their order status, fetching content and the pool exhausts quickly. Once exhausted, the request queue. The queue grows faster than it drains. Response times climb from milliseconds to seconds. Users, seeing a slow app, do what users do: they refresh. Each refresh generates another request. The queue grows faster.
This is connection pool exhaustion, the state where your application has more simultaneous database requests than its connection pool can service, causing requests to queue, time out, or fail.
The second database failure mode is query performance collapse. Many apps have queries that run acceptably on a small dataset but perform poorly as the table grows. A query that scans a user's table of 10,000 rows in 50 milliseconds takes 5,000 milliseconds on a table of 1,000,000 rows when the relevant column has no index. During a traffic spike, more concurrent queries run more slowly per query, compounding into something that looks, from the outside, like the app has simply stopped working.
The database fails first because it's the shared resource. Every part of the app, authentication, content retrieval, and order processing, depends on it. When the database slows, everything slows.
The authentication bottleneck: why login systems fail at scale in ways that surprise founders
Authentication is the second common failure point, and it surprises founders because it's usually the part of the app that got the most attention during development.
The problem isn't the login form. It's what happens behind the login form under concurrent load.
Most authentication systems validate users by querying the database. When a user submits their credentials, the auth system retrieves their record from the database, compares the submitted password against the stored hash, and issues a session token if the comparison succeeds. Each of these operations has a cost. The database query competes for connection pool resources. The password hash comparison is deliberately slow, a property of secure hashing algorithms like bcrypt, which are designed to be computationally expensive, specifically to resist brute-force attacks.
Under normal traffic, this is fine. During a spike when thousands of users are trying to log in simultaneously, the auth system issues thousands of computationally expensive hash comparisons while competing with every other part of the app for database connections. Session token validation, the check that runs on every authenticated request to confirm the token is valid, adds further database load on top of that.
The result is an authentication bottleneck: the login system is so resource-constrained that it can't process new attempts at the rate they're arriving. Users who submitted their credentials see a loading spinner that never resolves. They try again. Each retry is another queued request.
Stateless authentication, specifically JWT (JSON Web Tokens, a format that encodes user identity directly in the token so the server can validate it without a database lookup) addresses the core of this problem. Each validation reads the token itself rather than querying a session table. Under high concurrency, the reduction in database load is significant. It's an architectural decision that costs nothing extra to get right at the start but considerable engineering time to retrofit later.
Server capacity and what "running out of compute" looks like to a user
Server capacity failure is the most visible failure mode, but rarely the first. By the time the server is out of compute, the database has usually already become the constraint.
When a server runs out of capacity, specifically when CPU usage reaches its ceiling, and the server can no longer process incoming requests at the rate they arrive, the failure looks different depending on the infrastructure setup.
On a single server with no auto-scaling, requests queue at the server level. Response times climb. Memory pressure increases as queued requests accumulate in RAM. If memory is exhausted, the operating system starts terminating processes. The app crashes. Users see a connection timeout or a 502 Bad Gateway error, the web server's way of saying it has nothing left to give.
On infrastructure with horizontal scaling capacity, the ability to add more server instances to share the load, a traffic spike triggers new instances. This buys time. But if the database is already a bottleneck, adding more application servers makes the problem worse: more servers mean more concurrent connections competing for the same connection pool.
This is why scaling isn't a matter of adding more compute. The bottleneck shifts. You add servers and discover the database was the real ceiling. You address the connection pool and discover that the auth system is now the constraint. Each fix reveals the next limit.
The cascade effect: how one failure triggers the next
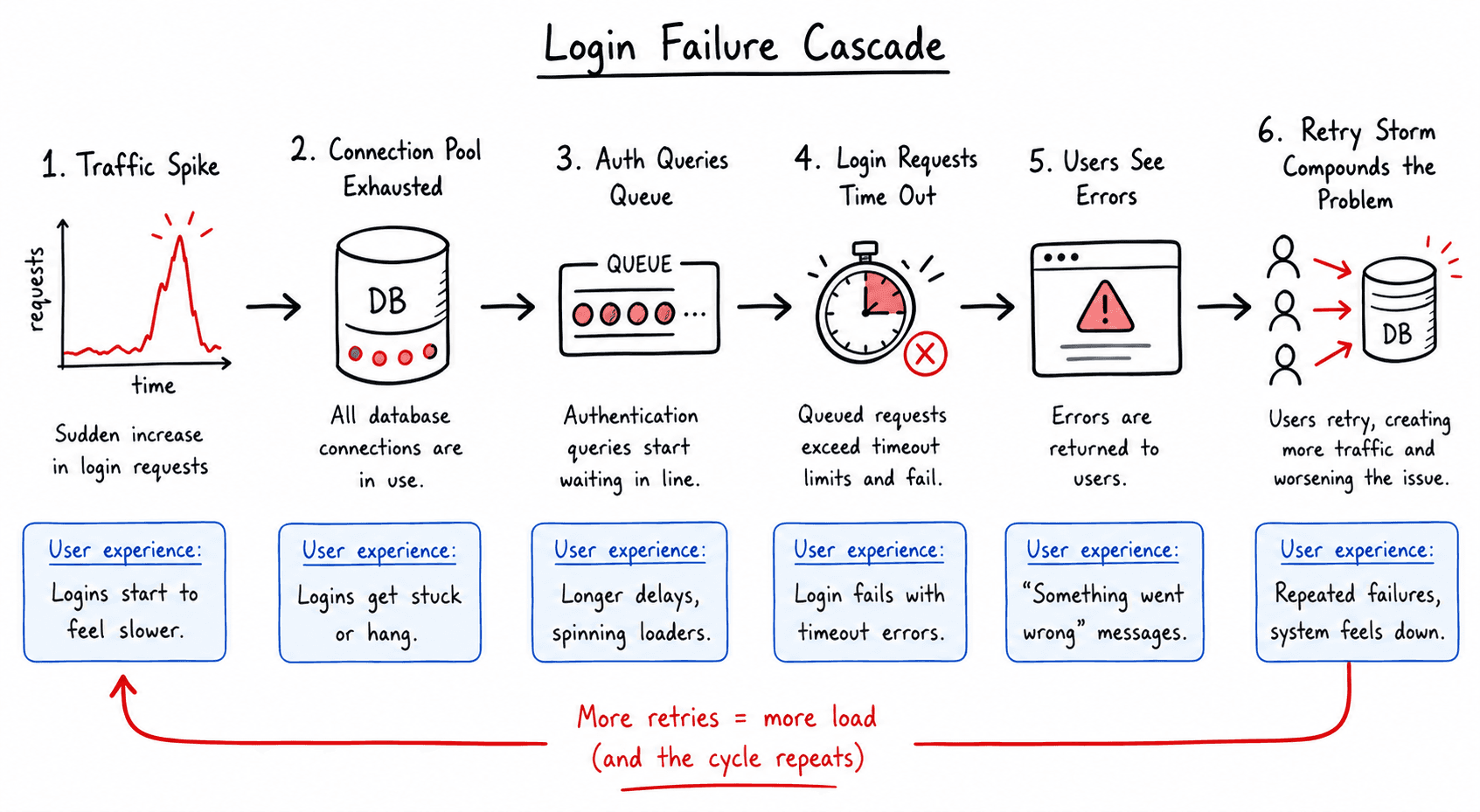
The cascade is the reason traffic spikes are so destructive relative to the severity of any individual failure.
Here's the sequence as it typically unfolds. A traffic spike arrives. The database connection pool is exhausted. Authentication queries that depend on database access begin queuing. Users attempting to log in see slow responses. Some wait. Many refresh or retry. Each retry is a new request competing for the same exhausted connection pool. The queue grows. Response times climb past the timeout thresholds set in the app's configuration. Requests begin failing. Users see error pages. Some retry immediately a pattern called a retry storm, where users responding to failure generate additional load that deepens the failure they're responding to.
Meanwhile, monitoring alerts start firing. The engineering team begins diagnosing the problem. But the cascade has already progressed: fixing the connection pool requires a configuration change and a deployment, both of which take time. During that time, the retry storm is sustaining the load created by the original spike.
The GitHub outage of October 2018 is a clean public example of this cascade structure. A database failover that should have been routine caused replication lag, leading to inconsistent data reads and application errors across multiple services. The postmortem is detailed and worth reading, not because GitHub's infrastructure resembles an early-stage startup's, but because the cascade logic is identical at any scale. One component's failure changes the conditions under which every dependent component operates.
The failure mode is predictable. Infrastructure designed with it in mind behaves differently under pressure than infrastructure that wasn't.
What production-ready infrastructure does differently to handle traffic spikes
The architectural decisions that determine whether an app survives a traffic spike are mostly made before the spike happens. They don't require large infrastructure budgets; they require knowing the failure modes in advance.
Properly configured connection pooling is first. A production-grade setup sizes the connection pool relative to expected peak load and implements a connection timeout that fails fast rather than queuing indefinitely. PgBouncer, a connection pooler for PostgreSQL, sits between the application and the database and manages connections more efficiently than most application frameworks do by default.
Stateless authentication, specifically JWT-based token validation, removes the database round-trip from every authenticated request. Under high concurrency, this reduces database load significantly and makes the auth system substantially more resilient to spikes.
Horizontal scaling capacity means that a spike that would overwhelm a single server is distributed across multiple instances. Auto-scaling, where the infrastructure automatically adds instances in response to CPU or traffic thresholds, handles spikes that arrive faster than a human can respond to.
Database indexing on the columns that take the most traffic, user identifiers, timestamps, and status fields means query performance doesn't collapse as table sizes grow under real user load.
When I reviewed how Mayson generates backend infrastructure, I found these decisions reflected in the output. Connection pooling configured. JWT-based auth. Infrastructure set up for horizontal scaling. The database schema was generated with indexing on expected high-traffic columns. For a founder whose app starts with this foundation, the spike failure modes described above are substantially less likely, not because the infrastructure is overbuilt, but because the known failure points have been addressed before the first user arrives.
What founders should ask before launch about their app's traffic ceiling
Most early-stage apps will never face a sudden viral traffic spike. Building for ten million concurrent users before you have ten paying customers adds infrastructure complexity that slows you down when moving quickly matters most. The goal here isn't to make launching feel dangerous. It's to help you ask the right questions before you find yourself reading your own postmortem.
The first question worth asking is what happens to your database under concurrent load. Not "is there a database" that's the baseline. Does it have a connection pool? Are there indexes on the columns your queries touch most? Has anyone run a basic load test with more than one simulated user?
The second is whether your authentication system is stateless. If session validation requires a database lookup on every authenticated request, you now know what that means under pressure. If it uses JWT or a similar stateless approach, that failure mode is substantially mitigated.
The third is where your backend lives and what you can see of it. If your backend is a managed third-party service, do you have access to connection pool metrics, query performance data, and error rates? Without those numbers, you don't know your traffic ceiling in advance; you discover it.
The fourth is whether your infrastructure can scale horizontally. Adding more of the same server instance should be a configuration change, not an architectural project.
None of these requires engineering expertise to ask. They require knowing enough to ask them. A tool or engineer who can't answer them clearly is a signal worth taking seriously before launch, not after.
Frequently asked questions
How many users can a typical MVP handle before things start breaking?
What does it actually look like when an app crashes under traffic? What do users see?
Can you fix a scaling problem after launch, or do you have to rebuild?
What is database connection pooling, and why does it matter for scaling?
How do I know if my app can handle a traffic spike before it happens?
Is there a way to build an app from the start that won't break under sudden traffic?
Navya has spent fifteen years building and breaking backend systems, mostly in payments and fintech. She now consults for engineering teams and writes about the technical concepts founders encounter when building real products. She is based in Bangalore.
When an app suddenly gets a lot of users, the parts that break first are almost always the database, the authentication system, and the server capacity, not because the code is wrong, but because these components were never stress-tested beyond the traffic levels the builder had in mind when they set the app up. The code that worked fine for 50 users starts behaving differently at 5,000, and the differences follow a predictable sequence. Engineers who've watched it happen can describe it in advance. This article does that.
Why sudden traffic is a different problem from steady growth
Steady growth gives infrastructure time to gradually reveal its limits. You notice that database queries are getting slower. You add an index. Response times improve. You notice the server is running hot. You upgrade the instance. You stay ahead of the problem because the problem arrives incrementally.
Sudden traffic doesn't give you that time. A product gets featured in a newsletter with a large readership. A tweet goes viral. A journalist covers the launch. Ten thousand people try to use an app that was built for a hundred, and they all try at the same moment. The infrastructure doesn't degrade; it collapses, because every weakness that would have revealed itself gradually over weeks arrives simultaneously in the first twenty minutes.
The failure sequence is also different. With gradual growth, you fix one thing at a time. With a traffic spike, you often can't fix anything in real time because the cascade has already started, and one failure is causing the next before you've diagnosed the first.
I've watched this happen from the inside once, during a payment infrastructure launch that got picked up by a financial news outlet the morning it went live. We had load-tested to three times the expected traffic. The actual spike was eleven times the expected traffic. The sequence of what broke, in what order, and why is something I can still describe in detail, and the sequence is almost always the same regardless of the app.
The database under pressure: what happens and why it's usually the first thing to go
The database fails first in almost every traffic spike. Understanding why requires knowing what a database connection pool is.
A connection pool is a set of pre-established connections between your application server and your database. Think of it as a limited number of phone lines between two offices. When your app needs to talk to the database, it borrows one of those lines, uses it, and returns it. If all the lines are in use when a new request arrives, that request waits. If it waits too long, it times out, and the user sees an error.
Under normal traffic, connection pools are sized generously relative to demand. Under a spike, every concurrent user is making requests that need database access, loading their profile, checking their order status, fetching content and the pool exhausts quickly. Once exhausted, the request queue. The queue grows faster than it drains. Response times climb from milliseconds to seconds. Users, seeing a slow app, do what users do: they refresh. Each refresh generates another request. The queue grows faster.
This is connection pool exhaustion, the state where your application has more simultaneous database requests than its connection pool can service, causing requests to queue, time out, or fail.
The second database failure mode is query performance collapse. Many apps have queries that run acceptably on a small dataset but perform poorly as the table grows. A query that scans a user's table of 10,000 rows in 50 milliseconds takes 5,000 milliseconds on a table of 1,000,000 rows when the relevant column has no index. During a traffic spike, more concurrent queries run more slowly per query, compounding into something that looks, from the outside, like the app has simply stopped working.
The database fails first because it's the shared resource. Every part of the app, authentication, content retrieval, and order processing, depends on it. When the database slows, everything slows.
The authentication bottleneck: why login systems fail at scale in ways that surprise founders
Authentication is the second common failure point, and it surprises founders because it's usually the part of the app that got the most attention during development.
The problem isn't the login form. It's what happens behind the login form under concurrent load.
Most authentication systems validate users by querying the database. When a user submits their credentials, the auth system retrieves their record from the database, compares the submitted password against the stored hash, and issues a session token if the comparison succeeds. Each of these operations has a cost. The database query competes for connection pool resources. The password hash comparison is deliberately slow, a property of secure hashing algorithms like bcrypt, which are designed to be computationally expensive, specifically to resist brute-force attacks.
Under normal traffic, this is fine. During a spike when thousands of users are trying to log in simultaneously, the auth system issues thousands of computationally expensive hash comparisons while competing with every other part of the app for database connections. Session token validation, the check that runs on every authenticated request to confirm the token is valid, adds further database load on top of that.
The result is an authentication bottleneck: the login system is so resource-constrained that it can't process new attempts at the rate they're arriving. Users who submitted their credentials see a loading spinner that never resolves. They try again. Each retry is another queued request.
Stateless authentication, specifically JWT (JSON Web Tokens, a format that encodes user identity directly in the token so the server can validate it without a database lookup) addresses the core of this problem. Each validation reads the token itself rather than querying a session table. Under high concurrency, the reduction in database load is significant. It's an architectural decision that costs nothing extra to get right at the start but considerable engineering time to retrofit later.
Server capacity and what "running out of compute" looks like to a user
Server capacity failure is the most visible failure mode, but rarely the first. By the time the server is out of compute, the database has usually already become the constraint.
When a server runs out of capacity, specifically when CPU usage reaches its ceiling, and the server can no longer process incoming requests at the rate they arrive, the failure looks different depending on the infrastructure setup.
On a single server with no auto-scaling, requests queue at the server level. Response times climb. Memory pressure increases as queued requests accumulate in RAM. If memory is exhausted, the operating system starts terminating processes. The app crashes. Users see a connection timeout or a 502 Bad Gateway error, the web server's way of saying it has nothing left to give.
On infrastructure with horizontal scaling capacity, the ability to add more server instances to share the load, a traffic spike triggers new instances. This buys time. But if the database is already a bottleneck, adding more application servers makes the problem worse: more servers mean more concurrent connections competing for the same connection pool.
This is why scaling isn't a matter of adding more compute. The bottleneck shifts. You add servers and discover the database was the real ceiling. You address the connection pool and discover that the auth system is now the constraint. Each fix reveals the next limit.
The cascade effect: how one failure triggers the next
The cascade is the reason traffic spikes are so destructive relative to the severity of any individual failure.
Here's the sequence as it typically unfolds. A traffic spike arrives. The database connection pool is exhausted. Authentication queries that depend on database access begin queuing. Users attempting to log in see slow responses. Some wait. Many refresh or retry. Each retry is a new request competing for the same exhausted connection pool. The queue grows. Response times climb past the timeout thresholds set in the app's configuration. Requests begin failing. Users see error pages. Some retry immediately a pattern called a retry storm, where users responding to failure generate additional load that deepens the failure they're responding to.
Meanwhile, monitoring alerts start firing. The engineering team begins diagnosing the problem. But the cascade has already progressed: fixing the connection pool requires a configuration change and a deployment, both of which take time. During that time, the retry storm is sustaining the load created by the original spike.
The GitHub outage of October 2018 is a clean public example of this cascade structure. A database failover that should have been routine caused replication lag, leading to inconsistent data reads and application errors across multiple services. The postmortem is detailed and worth reading, not because GitHub's infrastructure resembles an early-stage startup's, but because the cascade logic is identical at any scale. One component's failure changes the conditions under which every dependent component operates.
The failure mode is predictable. Infrastructure designed with it in mind behaves differently under pressure than infrastructure that wasn't.
What production-ready infrastructure does differently to handle traffic spikes
The architectural decisions that determine whether an app survives a traffic spike are mostly made before the spike happens. They don't require large infrastructure budgets; they require knowing the failure modes in advance.
Properly configured connection pooling is first. A production-grade setup sizes the connection pool relative to expected peak load and implements a connection timeout that fails fast rather than queuing indefinitely. PgBouncer, a connection pooler for PostgreSQL, sits between the application and the database and manages connections more efficiently than most application frameworks do by default.
Stateless authentication, specifically JWT-based token validation, removes the database round-trip from every authenticated request. Under high concurrency, this reduces database load significantly and makes the auth system substantially more resilient to spikes.
Horizontal scaling capacity means that a spike that would overwhelm a single server is distributed across multiple instances. Auto-scaling, where the infrastructure automatically adds instances in response to CPU or traffic thresholds, handles spikes that arrive faster than a human can respond to.
Database indexing on the columns that take the most traffic, user identifiers, timestamps, and status fields means query performance doesn't collapse as table sizes grow under real user load.
When I reviewed how Mayson generates backend infrastructure, I found these decisions reflected in the output. Connection pooling configured. JWT-based auth. Infrastructure set up for horizontal scaling. The database schema was generated with indexing on expected high-traffic columns. For a founder whose app starts with this foundation, the spike failure modes described above are substantially less likely, not because the infrastructure is overbuilt, but because the known failure points have been addressed before the first user arrives.
What founders should ask before launch about their app's traffic ceiling
Most early-stage apps will never face a sudden viral traffic spike. Building for ten million concurrent users before you have ten paying customers adds infrastructure complexity that slows you down when moving quickly matters most. The goal here isn't to make launching feel dangerous. It's to help you ask the right questions before you find yourself reading your own postmortem.
The first question worth asking is what happens to your database under concurrent load. Not "is there a database" that's the baseline. Does it have a connection pool? Are there indexes on the columns your queries touch most? Has anyone run a basic load test with more than one simulated user?
The second is whether your authentication system is stateless. If session validation requires a database lookup on every authenticated request, you now know what that means under pressure. If it uses JWT or a similar stateless approach, that failure mode is substantially mitigated.
The third is where your backend lives and what you can see of it. If your backend is a managed third-party service, do you have access to connection pool metrics, query performance data, and error rates? Without those numbers, you don't know your traffic ceiling in advance; you discover it.
The fourth is whether your infrastructure can scale horizontally. Adding more of the same server instance should be a configuration change, not an architectural project.
None of these requires engineering expertise to ask. They require knowing enough to ask them. A tool or engineer who can't answer them clearly is a signal worth taking seriously before launch, not after.
Frequently asked questions
How many users can a typical MVP handle before things start breaking?
What does it actually look like when an app crashes under traffic? What do users see?
Can you fix a scaling problem after launch, or do you have to rebuild?
What is database connection pooling, and why does it matter for scaling?
How do I know if my app can handle a traffic spike before it happens?
Is there a way to build an app from the start that won't break under sudden traffic?
Navya has spent fifteen years building and breaking backend systems, mostly in payments and fintech. She now consults for engineering teams and writes about the technical concepts founders encounter when building real products. She is based in Bangalore.
Featured Blogs
What breaks when your app suddenly gets a lot of users?

What does backend infrastructure mean in plain language?

I keep getting ₹5 lakh quotes from agencies just to test an idea — is there another way?
More Article by Mayson

How Parallel Building Lets Solo Developers Ship Like a Team of Five

Why Indie Devs Can't Ship Fast (And How to Eliminate Boilerplate for Good)

Why Backend Setup Takes Weeks (And How to Fix It)
On this page